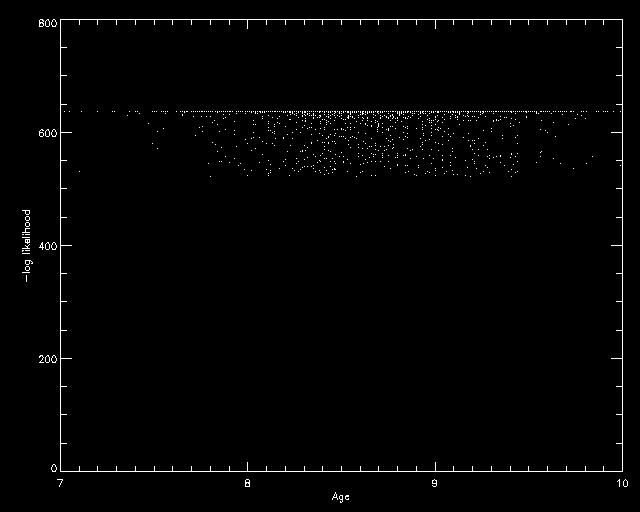
Well, I was getting delta functions again and way too large -log likelihoods. But now writing about this I realized that I was marginalizing over the other parameters before exponenting the -log likelihood. So now its turning out quite nicely.
I guess previous problems put me off the gridding method, but now I see that it is probably the way to go. The one problem is that I can't use U-B data without doing a for-loop to fit for E(U-B). IDL couldn't handle the size of array necessary to account for four variables.
So tomorrow, I will start running everything through this and test the effect of binary percentage. I think I'll start working on my final paper and presentation too while waiting for things to run.